Operational Data Feeds and Configuration Upload Wizards¶
Data Feeds and the Upload Wizards both provide ways to bulk upload data into paiyroll®:
Data Feeds are streamlined workflows for uploading common, regularly-used data which can be thought of a operational data (e.g. updating Shift payments).
Upload Wizards are for highly interactive uploads of what can be thought of as configuration data (e.g. adding new Departments).
Operational Data Feeds¶
Data Feeds are for operational data and are implemented using Reports:
The submission aspect of a Data Feed report implements the logic of the data feed.
The viewing aspect of a Data Feed report typically summarises the results of a data feed run.
There are several types of Data Feed:
Manual. Uses your browser to upload files into paiyroll® from your desktop.
Networked. Manual or automated pull of files by paiyroll® from the network.
A variant allows files to be pushed into paiyroll® from the network.
API pull. This allows paiyroll® to pull data from selected HR, T&A and other systems.
API push. This allows 3rd-party HR and T&A systems to push data into paiyroll®. See the Implementation Guide.
To use a Data Feed, create a Report Definition based on the required Report Template.
Report Template |
Type |
Notes |
|---|---|---|
Manual, Networked API push |
Loads holidays from CSV/ODS/XLSX files. Loads holidays from HR/T&A systems. |
|
Manual, Networked API push |
Loads Hours-only shifts, Payments and Deductions, and other Pay Items from CSV/ODS/XLSX files. Loads Hours-only shifts, Payments and Deductions, and other Pay Items from HR/T&A systems. |
|
Manual, Networked API push |
Loads Pay Items from CSV/ODS/XLSX files. Loads Pay Items from HR/T&A systems. |
|
Manual, Networked API push |
Loads salaries from CSV/ODS/XLSX files. Loads salaries from HR/T&A systems. |
|
Manual, Networked API push |
Loads shifts from CSV/ODS/XLSX files. Loads shifts from HR/T&A systems. |
|
Manual, Networked API push |
Loads GB SSP from CSV/ODS/XLSX files. Loads GB SSP from HR/T&A systems. |
|
Manual, Networked API push |
Loads GB workers from CSV/ODS/XLSX files. Loads GB workers from HR/T&A systems. |
|
API pull |
Synchronises with Cezanne HR system. |
|
API pull |
Synchronises with Driver Recruitment Software (DRS) system. |
|
API pull |
Synchronises with PeopleHR system. |
|
API pull |
Synchronises with StaffSavvy system. |
|
API pull |
Loads tax code and similar updates from HMRC. |
|
API pull |
Obsolete. Must be invoked after all pay runs for a tax year. |
Data Feeds are implemented using different engines depending on the type(s) in the table above. These engines provide standardisation of customisability (for transforming data), behaviour of the report (for networked data) and so on as described in the following sections.
Column transformation engine¶
Row-and-column-based data can be generated from any spreadsheet program, and other systems also them to support automation and integration. Data Feed Report Definitions allow such incoming data to be transformed as it is loaded using the following settings:
- Columns:
How each output column needed by paiyroll® is generated from the incoming data. The expected output column names depend on the Data Feed. The rows of the incoming data are transformed into the output using a Column definition language described below.
- CSV dialect:
For CSV files. See https://docs.python.org/library/csv.html#csv-fmt-params
- CSV fmtparams:
For CSV files. See https://docs.python.org/library/csv.html#csv-fmt-params
These reports also have both a submission aspect and a view aspect.
Column definition language¶
A set of columns is defined as follows:
columns ::= '{' column-definition [',' column-definition]... '}'
column-definition :: payroll-column: column-spec
column-spec ::= fmt [ '->' post-processor ]
payroll-column ::= An alphanumeric string, optionally ending with
"=default". If the ending is "=default" and the
column-spec evaluates to a blank, the "default"
(possibly blank) is used.
fmt ::= A Python format string.
post-processor ::= A Python expresssion.
The fmt is a Python format string
which can include fixed text (such as whitespace) and cell text using
replacement fields. The replacement fields use the column
headings from the input CSV file as the field_name, with any characters
not in the set VAR_CHARS removed. In this
example column-definition, the incoming CSV file has a column heading
“Worker.Id”, which is transformed into field_name “WorkerId” which is used
directly as the value of payroll-column “Works Id”:
"Works id": "{WorkerId}"
And here, “ref_t”, “row_number”, “Date”, “Client Name”, “Role Name” are transformed, combined and formatted using “[.] , ,” to form the “Display as” payroll-column value:
"Display as": "[{ref_t}.{row_number}] {Date}, {ClientName}, {RoleName}"
The fmt also allows limited processing of the cell text. For example:
fmt Usage |
Description |
|---|---|
|
Extract the “Email” cell and combine it with fixed text “ address”. |
|
Extract the “Name” cell, and use its first letter only. |
|
Extract the “AccountNumber” cell, zero fill to a width of 8, and add a preceding (single) “\\”. |
The result of the fmt is always stripped of any leading and trailing whitespace.
The optional post-processor is a Python expression used to apply more powerful transformations than the fmt supports. The expression can also use:
A variable called “_” initialised with the result of fmt.
Variables called “_1”, “_2”, etc. initialised with the result of each placeholder in fmt.
Most standard Python builtins, plus re, string, unicodedata, datetime from datetime, utc from datetime.timezone, timedelta from datetime.timedelta <https://docs.python.org/3/library/datetime.html#datetime.timedelta> and loads, dumps from json <https://docs.python.org/3/library/json.html>
A builtin one() which is like all() or any() but requires exactly one set value.
For example:
post-processor Usage |
Description |
|---|---|
|
Extract the “AccountNumber” cell, convert it to an int, multiply that by 100, zero fill to a width of 8, and add a preceding (single) “\\”. |
|
Extract the “Date” cell, parse it as %d/%m/%Y datetime, extract the date portion, and convert it into a string (in the default format, yyyy-mm-dd). |
|
Extract a day of the week from a date. |
|
Finds the first of cells A, B and C which is ‘YES’, and returns either ‘A’ or ‘B’ or ‘C’ accordingly. |
|
This is one possible way to eliminate accented characters. NOTE: this is a lossy process, and not recommended. Also, there are many possible variations of this that you may prefer. |
|
Provide a default value if the given value is blank. Here, if “Email” is blank, a default is derived from “Surname” and “Works Id”. |
|
Exclude rows without a value of ‘PAYE’ in “Contract” cell by using 1 or 0 skipped for CSV data-feed uploader. |
|
Load multiple shifts but exclude those with a value of zero: “£0.00@0.00hrs”. |
|
Remove “Limited “ and “ Ltd” in Display as field. |
|
Exclude “end_date” if it is after today. |
The result of the post-processor is NOT further normalised.
Networked File engines¶
This supports the file-based retrieval of data from external systems. In addition to capabilities of the Column transformation engine, Data Feed Report Definitions using these templates typically have some kind of credential settings; where needed these are stored in encrypted form.
These reports also have both a submission aspect and a view aspect.
The submission aspect provides for common error handling. In some cases, the network handling is specific to the data feed in question, but there are cases where a simple file transfer is involved where common handling is possible.
File pull¶
This data engine is mainly intended to be used by Payroll Debbie for automated fetching of files, nominally daily, but in the context of a pay schedule. The location of the fetched file is parameterised to handle common conventions used in this kind of networked data transfer; this is signified in the following using the notation “{placeholder}”.
- Run pattern:
Which days in the pay schedule should Debbie run this? We distinguish 4 parts of the the pay schedule:
“Idle” days.
The prompt days.
The approval days.
actual_t.
See Pay Schedule Terminology for details. The run pattern can be set to:
Idle days only, i.e. during the Idle window.
Prompt days only, i.e. during the Prompt window.
Idle and prompt days, i.e. spanning the Idle window and Prompt windows.
Note
Of course, the fetch can be performed manually, at any time.
- Start time:
From what hour of the day (UTC time) should {date} be set to the date of the fetch? Before this time, the previous day’s date will be used. For example, if the fetch time is “2022-01-02 10:23”, and start time is 11, the default value of {date} will be the previous day “2022-01-01”.
- Date adjustment:
By default, the {date} is set from the UTC run time (adjusted as described for start time). This default value may be adjusted forward or backward using this setting. Using the previous example, if the default is “2022-01-01” and the date adjustment is set to +1, the actual value of {date} will be “2022-01-02”.
- Fetch URL:
The file to be fetched is specified using a URL. The following formats are supported:
URL format details¶ Syntax
Details
Secure FTP (SFTP)
Overview:
sftp://[userinfo@]host[:port]/path
Note that the path portion of the URL is case-sensitive. Examples without and with {placeholder}:
sftp://hr.com:22/get/workers.csv sftp://t_n_a.eu/{date}_shifts.csv
Userinfo settings
If the authentication scheme is:
- None:
the userinfo is set from the Username setting.
- Password:
the userinfo is set from the Username and Password settings.
- Private key:
the userinfo is set from the Username setting.
Path details
The path can use placeholders and wildcard patterns. The following “{placeholder}” values are supported:
- {company}:
The Company legal_name.
- {date}:
A date in ISO format. Set from the UTC run time of the fetch, adjusted as described for Start time and Date adjustment. This is typically used to fetch files whose content relates to a given day.
- {frequency}:
The Pay Schedule frequency (i.e. “w1”, “m1” etc.)
- {pp_end}:
A date in ISO format. Set to the Pay Period end date using the Pay Schedule of the given Frequency. This is typically used to distinguish files whose content refers to a given pay period.
other usages of “{” and “}” must be doubled up. The path can include directory names as well as the final basename. The basename can contain wildcard patterns:
- *:
Matches everything.
- ?:
Matches any single character.
- [seq]:
Matches any character in seq.
- [!seq]:
Matches any char not in seq.
If wildcard patterns are used, the resulting matches are sorted alphabetically, and the last one used. For example, this basename:
sftp://t_n_a.eu/dir1/dir2/shifts*.csv
where dir1/dir2 contains:
shifts_2024_01_01.csv shifts_2024_01_01.1.csv
would fetch shifts_2024_01_01.csv, which may not be correct. Using an underscore “_” instead of the period “.”:
shifts_2024_01_01.csv shifts_2024_01_01_1.csv
would fetch shifts_2024_01_01_1.csv, as expected.
- Authentication scheme:
Authentication scheme details¶ Scheme
Details
None.
Uses Username setting. For sftp:, the remote system must have been configured for “passwordless login”.
Password.
Uses Username and Password settings.
Private key.
Uses Username and Private key settings. See below.
- Username:
Login name for remote site.
- Password:
Credentials.
- Private key:
Credentials. To use, the remote system must have been configured with the corresponding public key:
Typically, the paiyroll® administrator, or their IT department, would generate a public-private key pair. For example, using the OpenSSH command line tools like this:
$ ssh-keygen -f id_<short_descriptive_phrase>
will create a pair of files containing the public key and private key.
These would be held securely.
The public key can be sent using email, or other potentially insecure mechanism, to the remote system’s administrator to set it up.
The private key would be entered in the paiyroll® Report Definition.
File push¶
If your system can only push data towards paiyroll®, an SFTP destination can be provided for this data. paiyroll® can then fetch the data.
API-based integration¶
API pull¶
API pull supports the API-based fetch of data from external systems. Each Data Feed Report Definition’s settings will reflect the abilities and restrictions of the external system, and is backed by custom paiyroll® code.
API push, Implementation Guide¶
API push supports systems that can only push data to paiyroll® using OpenAPI 3.0 endpoints which facilitate data upload. The development effort for such integration typically requires:
An understanding of how the source data can be converted, including clarity on how any missing data is handled and what (if any) data is to be exposed for Employee self-service.
Authentication.
Detailed error handling and reporting.
paiyroll® exposes the capabilities of the Column transformation engine to simplify and reduce the development process to the following steps for these three areas:
Create a Data Feed Report Definition as if a manual file upload is being used. Use the “Columns” setting to configure any data transformation required.
Hint: Your HR or T&A system will often have an export-to-file capability, whose output can be used to bootstrap this procedure. Manually upload the exported file to test and debug the data transformations.
The result is a functioning set of data transformations, including handling of missing data, and automated support for self-service.
Write your code based on the previous step. The upload APIs use OAuth 2.0 authentication, expect the upload data as a series of “rows” in exactly the file format derived above, and return summary information (including errors and logs) which can be presented as required.
Hint. Use the Swagger workbench as described in the API User Guide to allocate API keys, and to explore the “upload” API.
The summary also includes a link to the detailed results, which can also be presented as required, or be viewed in the paiyroll® user-interface. The detailed results expand on the summary returned via the API by including:
Progress reporting in real time.
Additional summary and counter output.
Row-by-row error reporting.
Row-by-row change reporting.
The details results are also preserved from run-to-run and viewable for tracking purposes.
Taken together, note how this greatly reduces the 3rd-party code required to fulfil the functional and operational requirements on such integrations.
A note on object ids¶
The Data Feeds for Employees, Holidays and Sicknesses support two fields of particular interest to API push implementations as they are used internally to optimise the behaviour for this use case:
- uploaded:
A boolean field which defaults to, and should be set to, True. It can then be used to distinguish objects sourced through the API from objects created manually in paiyroll®.
- external_uid:
A string field (upto 64 long, to support at least a UUID) which should be set to the unique id of the object in the 3rd-party system.
Universal Data Feeds¶
Universal Auto Leaver¶
Automatically set end dates on workers who have not been aid for a set period. Each report definition specifies:
- Dry run:
If set, discard results and some errors become warnings
- Schedule:
Pay schedule
- Inactive Periods:
Inactive pay runs before leaver End date is set
Universal Upload holiday bookings¶
From CSV¶
The uploaded file uses Holiday-based Pay Items to describe holiday bookings. Each report definition specifies:
- Dry run:
If set, discard results and some errors become warnings
- Columns:
- CSV dialect:
- CSV fmtparams:
- Schedule:
Pay schedule
- Add from:
A test employee from which to seed pay items for new workers
- Skip rows:
Leading rows to skip
The file must conform to the following:
The content must be CSV format data. The exact style of CSV can be configured using the Report Definition. See Column transformation engine for details.
The first row must contain headings. Each heading will be converted into an input-column and each resulting input-column must be unique.
Each following row must define a single holiday booking, defined using the fields described below. Each field is extracted by transforming the data in the row using a set of input-columns and the Columns setting which is configured on the Report Definition.
- Works id:
The works_id of the worker.
- Worker name:
The name of the worker. Only used for diagnostic purposes.
- Start date:
Start day of holiday. ISO 8601 format, e.g. “2022-12-31”.
- End date:
End day of holiday. ISO 8601 format, e.g. “2022-12-31”.
- Start half-day late:
End in the morning. True/False.
- End half-day early:
Start in the afternoon. True/False.
- Days:
Net days, to 3 places.
- Comment:
Submitter comment.
- Remark:
Approver remark.
- Deleted:
Has this been deleted? True/False.
- UID:
Unique identifier.
Generally, each absence should be identified by its UID, a unique identifier which allows changes to be easily tracked. In some situations, no UID is available and this will greatly limit the ability for changes to be applied by paiyroll®. In these situations, the UID payroll-column specification can include a trailing “=” character. If present, the trailing “=”:
Allows the UID input-column to contain a blank value.
Examples:
If the CSV file has a column called “Starting date” which is exactly the same as the field “Start date”, the transform template would be simply:
"Start date": "{Startingdate}",
Complete example where no UID is available:
{ "Works id": "{WorkerId}", "Worker name": "{WorkerName}", "Start date": "{Startingdate}", "End date": "{Endingdate}", "Start half-day late": "False", "End half-day early": "False", "Days": "{Days}", "Comment": "", "Remark": "{Remark}", "Deleted": "{Deleted}", "UID": "=", }
Note how “Start half-day late” and “End half-day early” are hard-coded to “False” because the source system for this file does not support half-day holiday bookings:
From Network¶
The same as From CSV, except that the file is fetched from the network. Each report definition specifies:
- Dry run:
If set, discard results and some errors become warnings
- Columns:
- CSV dialect:
- CSV fmtparams:
- Schedule:
Pay schedule
- Add from:
A test employee from which to seed pay items for new workers
- Skip rows:
Leading rows to skip
- Run pattern:
Which days should Debbie run this? See run details
- Start time:
From what hour of the day (UTC time) should Debbie run this?
- Date adjustment:
By default, the {date} is set from the UTC run time
- Fetch URL:
See format details
- Authentication:
Authentication type
- Username:
Credentials
- Password:
Credentials
- Private key:
Include “—–BEGIN RSA PRIVATE KEY—–” and “—–END RSA PRIVATE KEY—–”
See File pull for details of the networking settings. Payroll Debbie uses the pay schedule related settings to automatically fetch the file and then initiate the upload of its data.
Warning
Payroll Debbie cannot guarantee the fetch will succeed, so the administrator should always check the uploaded data is as expected, and if necessary, rerun the upload manually.
Universal Upload pay items¶
This Universal Upload pay items facility uses the same file format is as the Upload Wizard for Pay Items, so each row can fully set up any Pay Item.
See also: Universal Upload pay item Columns and Universal Upload shifts.
From CSV¶
Each report definition specifies:
- Dry run:
If set, discard results and some errors become warnings
- Columns:
- CSV dialect:
- CSV fmtparams:
- Skip rows:
Leading rows to skip
The file must conform to the following:
The file must conform to the following:
The content must be CSV format data. The exact style of CSV can be configured using the Report Definition. See Column transformation engine for details.
The first row must contain headings. Each heading will be converted into an input-column and each resulting input-column must be unique.
Each following row must define a single pay item, defined using the fields described below. Each field is extracted by transforming the data in the row using a set of input-columns and the Columns setting which is configured on the Report Definition.
- Works id:
The works_id of the worker.
- Worker name:
The name of the worker. Only used for diagnostic purposes.
- Pay definition:
Name of any Pay Definition e.g. Bonus, Overtime.
- Frequency:
Only required if multiple frequencies e.g. m1 (monthly) or w1 (weekly).
- Input N:
The input values for N=0..19. The number and type of non-blank values depends on the Pay definition. See the Pay Item Editor for hints.
Examples:
Complete example:
{ "Works id": "{WorkerId}", "Worker name": "{WorkerName}", "Pay definition": "{PayType}", "Input 0": "{Amount}" }
Warning
Care should always be taken with files whose fields can be misinterpreted. For example, incorrect use of spreadsheet editing software can accidentally convert strings such as 000123 into the number 123.
From Network¶
The same as From CSV, except that the file is fetched from the network. Each report definition specifies:
- Dry run:
If set, discard results and some errors become warnings
- Columns:
- CSV dialect:
- CSV fmtparams:
- Skip rows:
Leading rows to skip
- Run pattern:
Which days should Debbie run this? See run details
- Start time:
From what hour of the day (UTC time) should Debbie run this?
- Date adjustment:
By default, the {date} is set from the UTC run time
- Fetch URL:
See format details
- Authentication:
Authentication type
- Username:
Credentials
- Password:
Credentials
- Private key:
Include “—–BEGIN RSA PRIVATE KEY—–” and “—–END RSA PRIVATE KEY—–”
See File pull for details of the networking settings. Payroll Debbie uses the pay schedule related settings to automatically fetch the file and then initiate the upload of its data.
Warning
Payroll Debbie cannot guarantee the fetch will succeed, so the administrator should always check the uploaded data is as expected, and if necessary, rerun the upload manually.
Universal Upload pay item Columns¶
This Universal Upload pay items Columns facility can upload:
Hours-only shifts. Similar to Universal Upload shifts, but uploads the Hours only. The Rates are held and managed in paiyroll® and only the Hours are exported from a T&A system.
Payments and Deductions.
All other Pay Items by named input.
See also: Universal Upload pay items and Universal Upload shifts.
Each row specifies an Employee, and input values on multiple Pay Items. For each Pay Item:
If all the inputs are blank, nothing is uploaded.
If all the numeric inputs are zero, and the Pay Item does not exist, nothing is uploaded.
If the Pay Item does not exist, the given inputs will be supplemented with the inputs from the pay definition (i.e. as a set of defaults).
The Pay Item will be created if necessary, and inputs uploaded to it.
Each column with an input value to be uploaded is processed as follows:
If the Columns setting maps the column heading to the name of a Pay Definition which is Shift-like, for example:
"Basic": "{BasicHours}", "Overtime15": "{OvertimeHours}", "Overtime20": "{WeekendHours}",
then single cell value is applied to the “hours” input.
Note that if the Pay Item has to be created, the Rate will be defaulted from the Pay Definition, so if per-Employee custom Rates are required, the Pay Item must be edited to set the required Rate. The Pay Item upload wizard (and the associated download capability) can be used to streamline this process.
Custom pre-processing allows each Shift-like Pay Item to be presented on payslips using a tailored, and automatically completed, “display-as” format. This can be used to show the details of the Shift worked (and so meet any statutory requirement for such granular information).
Otherwise, if the Columns setting maps a column heading to a Payment or Deduction Pay Definition name, for example:
"Expenses": "{Expenses}",
the single cell value is applied to the “basis” input.
Otherwise, the Columns setting(s) must map one or more column headings to Pay Definition name and input name pairs with a “.” in between, for example:
"Annual Salary.Next Base Salary": "{Salary}", "Annual Salary.Next Effective Date": "{EffectiveFrom}",
The cell values are applied to the named inputs.
From CSV¶
Each report definition specifies:
- Dry run:
If set, discard results and some errors become warnings
- Columns:
- CSV dialect:
- CSV fmtparams:
- Decimal places:
Rounding for numeric value
- Schedule:
Pay schedule
- Departments:
Restrict workers to a subset of the Schedule departments. No selection means all departments
- Skip rows:
Leading rows to skip
The file must conform to the following:
The content must be CSV format data. The exact style of CSV can be configured using the Report Definition. See Column transformation engine for details.
The first row must contain headings. Each heading will be converted into an input-column and each resulting input-column must be unique.
Each following row must define an Employee and one or more Pay Items, defined using the fields described below. Each field is extracted by transforming the data in the row using a set of input-columns and the Columns setting which is configured on the Report Definition.
- Works id:
The works_id of the worker.
- Worker name:
The name of the worker.
- Inputs 0-n:
The name of each column identifies the Pay Definition and one or more inputs as describe above.
Examples:
If the CSV file has a column called “Candidate Id” which is exactly the same as the field “Works id”, the transform template would be simply:
"Works id": "{CandidateId}",
Complete example for Hours-only shifts. Assume the “rate” inputs for workers A01 and B02 on Pay Items “Basic”, “Overtime15” and “Overtime20” have been preset as follows:
Rate settings¶ Worker
Basic rate
Overtime15 rate
Overtime20 rate
A01
5.00
7.50
10.00
B02
10.00
15.00
20.00
And assume the Column mapping is:
{ "Works id": "{CandidateId}", "Worker name": "{WorkerName}", "Expenses": "{Expenses}", "Basic": "{BasicHours}", "Overtime15": "{OvertimeHours}", "Overtime20": "{WeekendHours}", "Nighttime": "{NightHours}" }
Now we upload a CSV with input columns “BasicHours”, “OvertimeHours”, “WeekendHours” and cells as follows:
CSV content¶ WorksId
BasicHours
OvertimeHours
WeekendHours
…
A01
1
0
0
…
B02
1
1
1
…
The result is that worker A01 would be paid for 1 hour at his Std rate, while worker B02 would be paid for 1 hour at each of his Basic, Overtime15 and Overtime20 rates.
Warning
Care should always be taken with files whose fields can be misinterpreted. For example, incorrect use of spreadsheet editing software can accidentally convert strings such as 000123 into the number 123.
From Network¶
The same as From CSV, except that the file is fetched from the network. Each report definition specifies:
- Dry run:
If set, discard results and some errors become warnings
- Columns:
- CSV dialect:
- CSV fmtparams:
- Decimal places:
Rounding for numeric value
- Schedule:
Pay schedule
- Departments:
Restrict workers to a subset of the Schedule departments. No selection means all departments
- Skip rows:
Leading rows to skip
- Run pattern:
Which days should Debbie run this? See run details
- Start time:
From what hour of the day (UTC time) should Debbie run this?
- Date adjustment:
By default, the {date} is set from the UTC run time
- Fetch URL:
See format details
- Authentication:
Authentication type
- Username:
Credentials
- Password:
Credentials
- Private key:
Include “—–BEGIN RSA PRIVATE KEY—–” and “—–END RSA PRIVATE KEY—–”
See File pull for details of the networking settings. Payroll Debbie uses the pay schedule related settings to automatically fetch the file and then initiate the upload of its data.
Warning
Payroll Debbie cannot guarantee the fetch will succeed, so the administrator should always check the uploaded data is as expected, and if necessary, rerun the upload manually.
Universal Upload salaries¶
From CSV¶
The uploaded file uses Annual Salary-based Pay Items to describe salaries. Each report definition specifies:
- Dry run:
If set, discard results and some errors become warnings
- Columns:
- CSV dialect:
- CSV fmtparams:
- Schedule:
Pay schedule
- Skip rows:
Leading rows to skip
The file must conform to the following:
The file must conform to the following:
The content must be CSV format data. The exact style of CSV can be configured using the Report Definition. See Column transformation engine for details.
The first row must contain headings. Each heading will be converted into an input-column and each resulting input-column must be unique.
Each following row must define a single salary, defined using the fields described below. Each field is extracted by transforming the data in the row using a set of input-columns and the Columns setting which is configured on the Report Definition.
- Works id:
The works_id of the worker.
- Worker name:
The name of the worker. Only used for diagnostic purposes.
- Salary:
Annual salary.
- Effective Date:
Date when salary takes effect. ISO 8601 format, e.g. “2022-12-31”.
- Deleted:
Has this been deleted? True/False.
Examples:
If the CSV file has a column called “Effective from” which is exactly the same as the field “Effective id”, the transform template would be simply:
"Effective Date": "{Effectivefrom}",
Complete example:
{ "Works id": "{WorkerId}", "Worker name": "{WorkerName}", "Salary": "{Salary}", "Effective Date": "{Effectivefrom}", "Deleted": "{Deleted}" }
Warning
Care should always be taken with files whose fields can be misinterpreted. For example, incorrect use of spreadsheet editing software can accidentally convert strings such as 000123 into the number 123.
From Network¶
The same as From CSV, except that the file is fetched from the network. Each report definition specifies:
- Dry run:
If set, discard results and some errors become warnings
- Columns:
- CSV dialect:
- CSV fmtparams:
- Schedule:
Pay schedule
- Skip rows:
Leading rows to skip
- Run pattern:
Which days should Debbie run this? See run details
- Start time:
From what hour of the day (UTC time) should Debbie run this?
- Date adjustment:
By default, the {date} is set from the UTC run time
- Fetch URL:
See format details
- Authentication:
Authentication type
- Username:
Credentials
- Password:
Credentials
- Private key:
Include “—–BEGIN RSA PRIVATE KEY—–” and “—–END RSA PRIVATE KEY—–”
See File pull for details of the networking settings. Payroll Debbie uses the pay schedule related settings to automatically fetch the file and then initiate the upload of its data.
Warning
Payroll Debbie cannot guarantee the fetch will succeed, so the administrator should always check the uploaded data is as expected, and if necessary, rerun the upload manually.
Universal Upload shifts¶
This Universal Upload shifts facility is optimised for Shift-like Pay Items and is typically used with data exported from a T&A system:
Before the new Shift-like Pay Items are uploaded, all existing matching Pay Items are deleted. This makes it easy to refine the data over a pay period.
Custom pre-processing allows each Shift-like Pay Item to be presented on payslips using a tailored, and automatically completed, “display-as” format. This can be used to show the details of the Shift worked (and so meet any statutory requirement for such granular information).
See also Universal Upload pay items and Universal Upload pay item Columns.
From CSV¶
The uploaded file uses PayPer-based and MinimumWage-based Pay Items to describe shifts worked. Each report definition specifies:
- Dry run:
If set, discard results and some errors become warnings
- Pay items:
The names of the pay items
- Columns:
- CSV dialect:
- CSV fmtparams:
- Decimal places:
Rounding for Rate and Units
- Schedule:
Pay schedule
- Departments:
Restrict workers to a subset of the Schedule departments. No selection means all departments
- Skip zeroes:
Ignore, rather than warn on, on zero or blank values
- Filter pay period:
Filter out any dates outside the pay period
- Skip rows:
Leading rows to skip
The file must conform to the following:
The content must be CSV format data. The exact style of CSV can be configured using the Report Definition. See Column transformation engine for details.
The first row must contain headings. Each heading will be converted into an input-column and each resulting input-column must be unique.
Each following row must define a single worked shift, defined using the fields described below. Each field is extracted by transforming the data in the row using a set of input-columns and the Columns setting which is configured on the Report Definition. In addition the CSV engine adds predefined input-columns for row_number and ref_t specifying the upload date and, for the Display as only, a shift_number.
- Works id:
The works_id of the worker.
- Worker name:
The name of the worker.
- Rate:
The pay rate as a float.
- Units:
The units worked as a float.
- Display as:
An arbitrary string identifying the shift.
By default, the Rate and Units values are expected to be non-zero, and rows with zero values are counted and cause a warning. However, the Skip zeroes setting can be used to silently ignore such rows where the CSV normally contains unwanted zero values.
Examples:
If the CSV file has a column called “Candidate Id” which is exactly the same as the field “Works id”, the transform template would be simply:
"Works id": "{CandidateId}",
If the CSV file has columns called “Shift-location” and “Shift-date”, the “Display as” field could be set to:
"{row_number}: {CandidateId} worked at {Shiftlocation} on {Shiftdate}"
Complete example:
{ "Works id": "{WorkerId}", "Worker name": "{WorkerName}", "Rate": "{HiringRate}", "Units": "{TotalHours}", "Display as": "{row_number}: {Date}, {ClientName}, {RoleName}" }
Warning
Care should always be taken with files whose fields can be misinterpreted. For example, incorrect use of spreadsheet editing software can accidentally convert strings such as 000123 into the number 123.
From Network¶
The same as From CSV, except that the file is fetched from the network. Each report definition specifies:
- Dry run:
If set, discard results and some errors become warnings
- Pay items:
The names of the pay items
- Columns:
- CSV dialect:
- CSV fmtparams:
- Decimal places:
Rounding for Rate and Units
- Schedule:
Pay schedule
- Departments:
Restrict workers to a subset of the Schedule departments. No selection means all departments
- Skip zeroes:
Ignore, rather than warn on, on zero or blank values
- Filter pay period:
Filter out any dates outside the pay period
- Skip rows:
Leading rows to skip
- Run pattern:
Which days should Debbie run this? See run details
- Start time:
From what hour of the day (UTC time) should Debbie run this?
- Date adjustment:
By default, the {date} is set from the UTC run time
- Fetch URL:
See format details
- Authentication:
Authentication type
- Username:
Credentials
- Password:
Credentials
- Private key:
Include “—–BEGIN RSA PRIVATE KEY—–” and “—–END RSA PRIVATE KEY—–”
See File pull for details of the networking settings. Payroll Debbie uses the pay schedule related settings to automatically fetch the file and then initiate the upload of its data.
Warning
Payroll Debbie cannot guarantee the fetch will succeed, so the administrator should always check the uploaded data is as expected, and if necessary, rerun the upload manually.
GB Data Feeds¶
GB Upload SSP¶
From CSV¶
The uploaded file adds or updates SSP absences. Each report definition specifies:
- Dry run:
If set, discard results and some errors become warnings
- Columns:
- CSV dialect:
- CSV fmtparams:
- Schedule:
Pay schedule
- Add from:
A test employee from which to seed pay items for new workers
- Skip rows:
Leading rows to skip
The file must conform to the following:
The content must be CSV format data. The exact style of CSV can be configured using the Report Definition. See Column transformation engine for details.
The first row must contain headings. Each heading will be converted into an input-column and each resulting input-column must be unique.
Each following row must define a single SSP absence, define using the fields described below. Each field is extracted by transforming the data in the row using a set of input-columns and the Columns setting which is configured on the Report Definition. In addition the CSV engine adds a predefined input-column for row_number.
- Works id:
The works_id of the worker.
- Worker name:
The name of the worker. Only used for diagnostic purposes.
- Start date:
Start day of holiday. ISO 8601 format, e.g. “2022-12-31”.
- End date:
End day of holiday. ISO 8601 format, e.g. “2022-12-31”.
- Comment:
Submitter comment.
- Remark:
Approver remark.
- Deleted:
Has this been deleted? True/False.
- Start Comment:
Submitter comment on start.
- Start Remark:
Approver remark on start.
- UID:
Unique identifier.
- Qualifying:
Stautory declaration. True/False.
- COVID-19:
Stautory declaration. True/False.
Generally, each absence should be identified by its UID, a unique identifier which allows changes to be easily tracked. In some situations, no UID is available and this will greatly limit the ability for changes to be applied by paiyroll®. In these situations, the UID payroll-column specification can include a trailing “=” character. If present, the trailing “=”:
Allows the UID input-column to contain a blank value.
Allows the End date input-column to contain a blank value. If not set:
Examples:
Complete example where no UID is available:
{ "Works id": "{WorkerId}", "Worker name": "{WorkerName}", "Start date": "{Start}", "End date": "{End}", "Comment": "", "Remark": "{Remark}", "Deleted": "{Deleted}", "Start Comment": "", "Start Remark": "{StartRemark}", "UID": "=", "Qualifying": "{Qualifying}", "COVID-19": "{COVID-19}" }
From Network¶
The same as From CSV, except that the file is fetched from the network. Each report definition specifies:
- Dry run:
If set, discard results and some errors become warnings
- Columns:
- CSV dialect:
- CSV fmtparams:
- Schedule:
Pay schedule
- Add from:
A test employee from which to seed pay items for new workers
- Skip rows:
Leading rows to skip
- Run pattern:
Which days should Debbie run this? See run details
- Start time:
From what hour of the day (UTC time) should Debbie run this?
- Date adjustment:
By default, the {date} is set from the UTC run time
- Fetch URL:
See format details
- Authentication:
Authentication type
- Username:
Credentials
- Password:
Credentials
- Private key:
Include “—–BEGIN RSA PRIVATE KEY—–” and “—–END RSA PRIVATE KEY—–”
See File pull for details of the networking settings. Payroll Debbie uses the pay schedule related settings to automatically fetch the file and then initiate the upload of its data.
Warning
Payroll Debbie cannot guarantee the fetch will succeed, so the administrator should always check the uploaded data is as expected, and if necessary, rerun the upload manually.
GB Upload workers¶
From CSV¶
The uploaded file adds or updates workers. Each report definition specifies:
- Dry run:
If set, discard results and some errors become warnings
- Columns:
- CSV dialect:
- CSV fmtparams:
- Add from:
A test employee from which to seed pay items for new workers
- Invite:
Send password set welcome email
- Auto works id:
Automatically generate sequential works id
- Disable employee updates:
Disable employee self-service updates
- Schedule:
Pay schedule
- Worker key:
Primary identifier for a worker
- Skip rows:
Leading rows to skip
The file must conform to the following:
The content must be CSV format data. The exact style of CSV can be configured using the Report Definition. See Column transformation engine for details.
The first row must contain headings. Each heading will be converted into an input-column and each resulting input-column must be unique.
Each following row must define a single worker, define using the fields described below. Each field is extracted by transforming the data in the row using a set of input-columns and the Columns setting which is configured on the Report Definition. In addition the CSV engine adds a predefined input-column for row_number.
The available fields are country dependent, but fall into the following groups:
- <common>:
Country-independent fields such as “title”, “name” and “works_id”. Existing workers are matched by the “username” field and updated. If no existing worker is matched, a new worker is created.
- <postaldetail>:
Postal details, prefixed by “postaldetail.”.
- <taxdetail>:
Employer-specified tax details, prefixed by “taxdetail.”.
- <taxeedetail>:
Worker-specified tax details, prefixed by “taxeedetail.”.
- <bankdetail>:
Banking details, prefixed by “bankdetail.”.
By default, the file overwrites every field of any existing worker. But, depending on the completeness of the source data, this is not desirable after an initial upload because certain fields are effectively managed, and may have been updated, using paiyroll®. In these situations, the payroll-column specification can include a trailing “=” character. If present, the trailing “=”:
Allows the input-columns to contain a blank value for existing workers. For new workers, non-blank values must continue to be supplied (for payroll-columns without a default value).
Preserves the existing value on the worker.
Examples:
Working days is an array of boolean values that specifies the weekly working pattern. Notice how the “working_days” are specified using doubled “{{” and “}}” to escape interpretation as a key name:
"{{true,true,true,true,true,true,true}}"
Complete example:
{ "username: "{EmailAddress} -> _.lower()", "email: "{EmailAddress} -> _.lower()", "is_active=True: "", "title: "", "name: "{WorkerName}", "mobile: "+{PhoneCountryCode}{PhoneNumber}", "preferences={}: "", "uploaded=: "True", "external_uid=: "", "works_id: "{WorkerId}", "start_date: "{Start date}", "working_days: "{{true,true,true,true,true,false,false}}", "fte: "", "end_date: "", "original_start_date: "", "department: "Workers", "existing_employee=False: "", "notes: "", "data: "", "cost_centres: "", "postaldetail.line1: "{AddressLine1}", "postaldetail.line2: "{AddressLine2}", "postaldetail.line3: "{Town}", "postaldetail.line4: "{County}", "postaldetail.postcode: "{Postcode}", "postaldetail.foreign_country: "", "taxdetail.weekly_hours_worked=Other: "", "taxdetail.P45_tax_code=: "", "taxdetail.P45_week1_month1=False: "", "taxdetail.P45_leaving_date=: "", "taxdetail.P45_total_pay_to_date=: "", "taxdetail.P45_total_tax_to_date=: "", "taxdetail.P45_continue_student_loan=0: "", "taxdetail.P45_continue_postgraduate_loan=0: "", "taxdetail.NI_category=General: "", "taxdetail.workplace_postcode=: "", "taxdetail.director=False: "", "taxdetail.director_from=: "", "taxdetail.director_NI_cumulative=False: "", "taxdetail.paid_irregularly=False: "", "taxdetail.off_payroll_worker=False: "", "taxdetail.migrated_rti_payid=: "", "taxdetail.cis=: "", "taxeedetail.date_of_birth: "{DateofBirth} -> str(datetime.strptime(_, '%d/%m/%Y').date())", "taxeedetail.gender: "{Gender}", "taxeedetail.NI_number: "{NINumber}", "taxeedetail.employee_statement: "", "taxeedetail.student_loan=0: "", "taxeedetail.postgraduate_loan=0: "", "taxeedetail.cis_trading_name=: "", "taxeedetail.cis_utr=: "", "taxeedetail.cis_crn=: "", "bankdetail.account_name: "{WorkerName} -> re.sub('[^A-Z0-9.&/ -]', '', _[:35].upper()) or '-'", "bankdetail.payment_method=: "", "bankdetail.sort_code: "000000", "bankdetail.account_number: "00000000", }
Warning
Care should always be taken with files whose fields can be misinterpreted. For example, incorrect use of spreadsheet editing software can accidentally convert strings such as 000123 into the number 123.
From Network¶
The same as From CSV, except that the file is fetched from the network. Each report definition specifies:
- Dry run:
If set, discard results and some errors become warnings
- Columns:
- CSV dialect:
- CSV fmtparams:
- Add from:
A test employee from which to seed pay items for new workers
- Invite:
Send password set welcome email
- Auto works id:
Automatically generate sequential works id
- Disable employee updates:
Disable employee self-service updates
- Schedule:
Pay schedule
- Worker key:
Primary identifier for a worker
- Skip rows:
Leading rows to skip
- Run pattern:
Which days should Debbie run this? See run details
- Start time:
From what hour of the day (UTC time) should Debbie run this?
- Date adjustment:
By default, the {date} is set from the UTC run time
- Fetch URL:
See format details
- Authentication:
Authentication type
- Username:
Credentials
- Password:
Credentials
- Private key:
Include “—–BEGIN RSA PRIVATE KEY—–” and “—–END RSA PRIVATE KEY—–”
See File pull for details of the networking settings. Payroll Debbie uses the pay schedule related settings to automatically fetch the file and then initiate the upload of its data.
Warning
Payroll Debbie cannot guarantee the fetch will succeed, so the administrator should always check the uploaded data is as expected, and if necessary, rerun the upload manually.
GB Cezanne HR API¶
Synchronises with Cezanne HR system via API calls. See Integrate with Cezanne HR API for usage notes. Each report definition specifies:
- Dry run:
If set, discard results and some errors become warnings
- Client Id:
Id for authentication
- Client Secret:
Secret for authentication
- Authorisation:
Enable delegated access
- Excluded:
Contract Term(s) to exclude, semi-colon separated
- Add from:
A test employee from which to seed pay items for new workers
- Invite:
Send password set welcome email
- Schedule:
Pay schedule
- Companies:
Semi-colon separated companies, blank for all
- Rewind:
If set, starts fetch from 3 months ago. Default starts from last run
- Sync from:
A test employee from which to seed pay items for salaries and absences
- Working days:
If set, Cezanne HR controls working days
- Enable Sickness:
Clear to disable Sickness
- Enable Holidays:
Clear to disable Holiday
GB Driver Recruitment Software (DRS) API¶
Synchronises with Driver Recruitment Software (DRS) system via API calls. See Integrate with Driver Recruitment Software API for usage notes. Each report definition specifies:
- Dry run:
If set, discard results and some errors become warnings
- API endpoint:
URL allocated to you by DRS
- Username:
Credentials
- Password:
Credentials
- Schedule:
Pay schedule
- Run pattern:
Which days should Debbie run this? See run details
- Start time:
From what hour of the day (UTC time) should Debbie run this?
- Shifts:
Shift pay items e.g. Shift {shift_number}
- Expenses:
Expenses pay items e.g. Expenses {shift_number}
- VAT:
VAT pay items e.g. VAT {shift_number}
- Other:
Other pay items e.g. Other {shift_number} (leave blank if not used)
- Other2:
Other2 pay items e.g. Other2 {shift_number} (leave blank if not used)
- Other3:
Other3 pay items e.g. Other3 {shift_number} (leave blank if not used)
- Holiday:
Holiday pay item
- Excluded:
Contract Type(s) to exclude, semi-colon separated
- Add from:
A test employee from which to seed pay items for new workers
- Invite:
Send password set welcome email
GB PeopleHR API¶
Synchronises Workers, Salary, Holiday, Recurring Benefits, Ad-hoc Payments, Ad-hoc Deductions and Pensions from an external PeopleHR system via API calls. See Integrate with PeopleHR API for usage notes. Each report definition specifies:
- Dry run:
If set, discard results and some errors become warnings
- Add from:
A test employee from which to seed pay items for new workers
- Invite:
Send password set welcome email
- API key:
API key for authentication
- Salary query:
Blank query disables salary updates
- Holiday query:
Blank query disables holiday updates
- Excluded:
Employment Type(s) to exclude, semi-colon separated
- Schedule:
Pay schedule
- Companies:
Semi-colon separated companies, blank for all
- Sync from:
A test employee from which to seed pay items for salaries and absences
- Rewind:
If set, starts fetch from 3 months ago. Default starts from last run
- Recurring Benefit query:
Blank disables updates
- Recurring Benefit query columns:
- Single Payment query:
Blank disables updates
- Single Payment query columns:
- Single Deduction query:
Blank disables updates
- Single Deduction query columns:
- Pension query:
Blank disables updates
- Pension query columns:
GB StaffSavvy API¶
Synchronises Workers, Salary, Shifts and Holiday from an external StaffSavvy system via API calls. See Integrate with StaffSavvy API for usage notes. Each report definition specifies:
- Dry run:
If set, discard results and some errors become warnings
- API user:
Id for authentication (x-user)
- API key:
Secret for authentication (x-auth)
- Add from:
A test employee from which to seed pay items for new workers
- Sync from:
A test employee from which to seed pay items for salaries and absences
- Invite:
Send password set welcome email
- Excluded:
Contract Type(s) to exclude, semi-colon separated
- Departments:
Semi-colon separated departments, blank for all
- Schedule:
Pay schedule
- Rewind:
If set, starts fetch from 3 months ago. Default starts from last run
- Paiyroll Workers Report:
URL from “Reports->Manage Custom Reports->More->View details”
- Paiyroll Salaries Report:
URL from “Reports->Manage Custom Reports->More->View details”
- Shifts:
Shift pay items e.g. Shift {shift_number}. Clear to disable Shift fetch
- Skip zeroes:
Ignore, rather than warn on, on zero or blank values
- Enable Holidays:
Clear to disable Holiday
- Enable Sickness:
Clear to disable Sickness
GB HMRC CIS Verification¶
This Data Feed’s submission aspect fetches Construction Industry Scheme tax information from HMRC and applies them to workers. It is broadly analagous GB HMRC DPS for normally taxed workers. Each report definition specifies:
- Dry run:
If set, discard results and some errors become warnings
- CIS username:
Alternatively, RTI username can be used
- CIS password:
Alternatively, RTI password can be used with RTI username
Reports based on this template can use Shared Credentials.
GB HMRC DPS¶
This Data Feed’s submission aspect fetches PAYE and tax code (P6 and P9), student loan and post-graduate loan (SL and PGL) updates from HMRC’s Data Provisioning Service and applies them to workers. Other notifications are also fetched and stored.
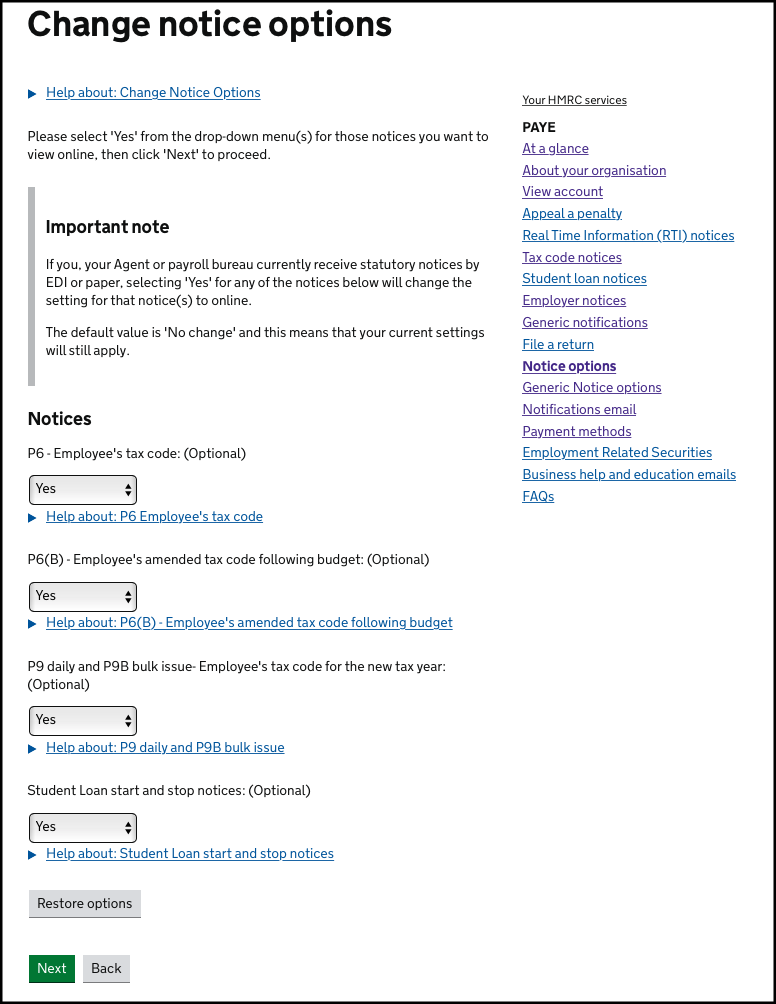
Before you can use this service, all notice options need to be set to online in your HMRC PAYE services. To change notice options, navigate to:
Messages > PAYE for employers messages > Change how you get tax code and student loan notices
Ensure all options are set to YES and press NEXT (noting that only future notices issued after this change will be available online for this data feed):
Each report definition specifies:
- Dry run:
If set, discard results and some errors become warnings
- DPS username:
Government Gateway user ID
- DPS password:
Password
- Rewind:
Leave unset to fetch from last run or 90-days ago
Reports based on this template can use Shared Credentials.
The results of the submission aspect are recorded and can be seen in the view aspect using the history on My Data Feeds:
PAYE updates by worker:
1762: {'PAYE.Tax code': '944L', 'PAYE.Effective date': '2014-05-18', 'PAYE.Previous pay': '2200.00', 'PAYE.Previous tax': '315.00'}
Tax code updates by worker:
1762: {'PAYE.Tax code': '944L', 'PAYE.Effective date'}
SL updates by worker:
1762: {'SL.LoanStartDate': '2016-07-17', 'SL.Plan type': '02'} 1768: {'SL.StopDate': '2014-02-06'} 2762: {'SL.LoanStartDate': '2019-04-10', 'SL.PGL': True}
NI number updates by worker:
1762: 'SH445566A' 2762: ''
Other notifications in generic form:
{ 'date': '2013-09-23', 'title': 'Late filing notice', 'text': "Our records indicate that your Full Payment Submission (FPS) dated 15/09/2013 was sent late. You must send an FPS on, or before, the time you pay your employees. In future, please ensure that your FPSs are sent on time. From April 2014, you may incur penalties if you file your FPSs late.\nIf you think this notice is incorrect please contact HMRC's Employer Helpline.", 'content': { 'Information': { 'InformationItem': { 'DisplayName': 'Date of Receipt', 'Value': '2013-09-15' } } } } { 'date': '2013-09-23', 'title': 'Invalid DOB', 'text': 'Change DOB 03/02/1975 to 03/02/1982, DOB 02/08/1990 to 12/08/1990, DOB 31/09/1985 to 21/09/1985 for Shawcross.', 'content': { 'Change': { 'ActionItem': {'DisplayName': 'Date of Birth', 'PreviousValue': '1990-08-02', 'Value': '1990-08-12'} } } } { 'EmployerDetails': { 'EmployerRef': '123/1739465', 'HMRCoffice': {...}, 'Name': "Andy's Joinery Services", 'Address': {'Line': 'Any City', 'PostCode': 'CC22 2CC'}, 'AORef': '234PL5678901' }, 'NotificationText': "Notification to complete a PAYE Annual Return. This notice requires you...", 'FormType': 'P35', 'HeaderText': 'PAYE instructions to employers', 'IssueDate': '2013-05-02', 'SequenceNumber': '3226', 'TaxYearEnd': '2014' }
GB PAYE tax code changer (P9X)¶
This data feed updates tax codes at the end of the tax year. It must be invoked after all pay schedules for a Company have had their last pay run for the tax year, and before the first pay runs of the new tax year.
Each report definition specifies:
- Dry run:
If set, discard results and some errors become warnings
The results of the submission aspect are recorded and can be seen in the view aspect using the history on My Data Feeds, tax code updates by worker:
1762, '944L', '920L'
Configuration Upload Wizards¶
There are Upload Wizards for most configuration data such as:
Employees
Departments
The data supplied by the uploaded file is different in each case, and listed when the Upload button is selected on the relevant object listing page. (See Importers for information on uploading an entire company structure).
Generally, the interactive nature of the wizard facilitates review of the data being imported, and so reduces the chance of error. For most fields, the format of the data being uploaded is clear from the context.
Warning
Care should always be taken with files whose fields can be misinterpreted. For example, incorrect use of spreadsheet editing software can accidentally convert strings such as 000123 into the number 123.
See also paiyroll® Importers which an entire company structure to be uploaded and The Toolshed which supports repeated and specialised changes.
Foreign keys¶
However, fields which represent links in the database (i.e. foreign keys) must convey extra information to allow the linkage to be created. This is done using a “;” to split the field as needed:
value1;value2
For example, the Employee upload must specify:
- title:
This is a link to the Title, and so is simply specifed as the text equivalent of the Title, for example:
Mr.
- company:
This is a link to a Company, and must be specified using the text equivalent of the Client and Company, for example:
ACME group;Drilling Ltd
- department:
This is a link to a Department, and must be specified using the text equivalent of the Company and the Department. However, since the Company must be specified as above, this second level of “;” must be escaped:
ACME group\;Drilling Ltd;Audit and Accounts